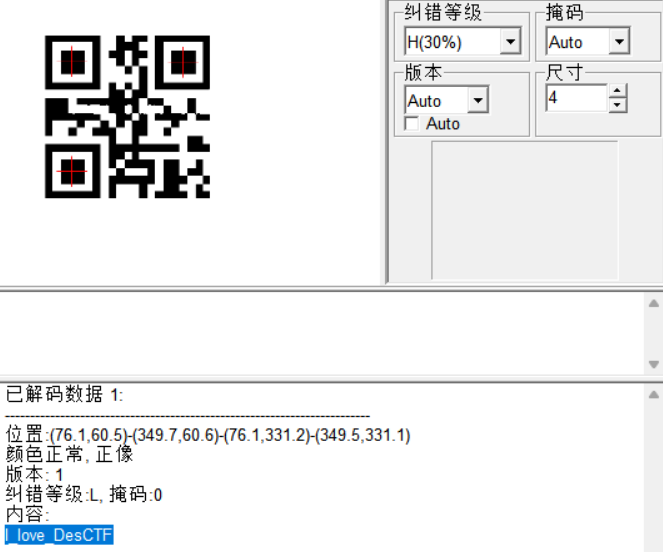
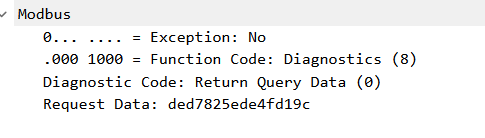
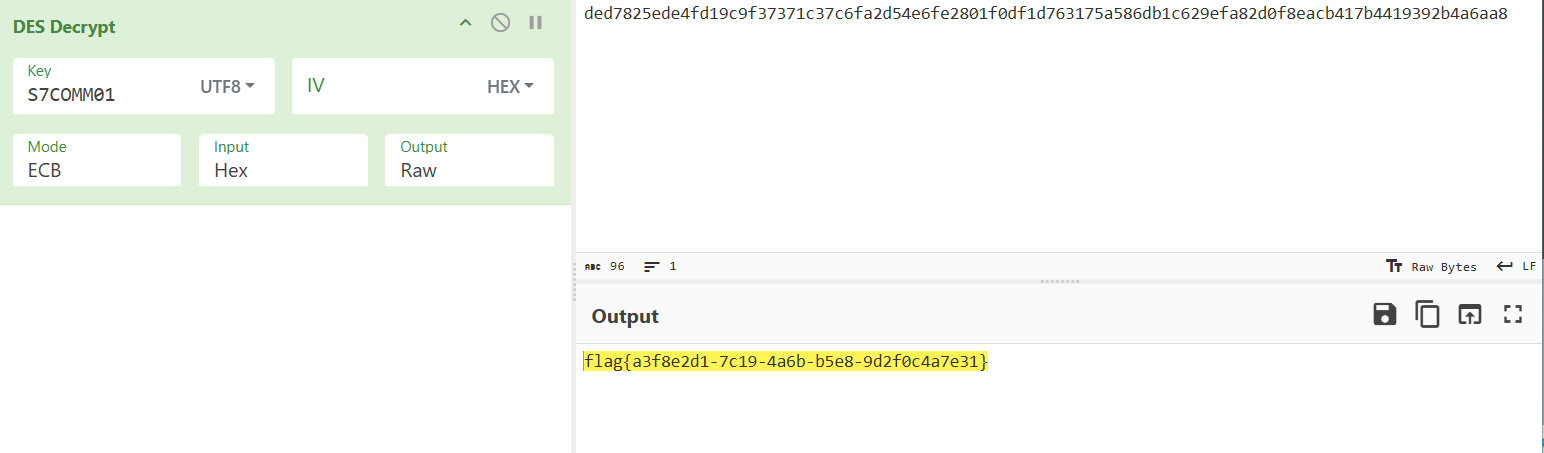
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
|
"""
红外遥控序列解码辅助脚本
核心思路:
1) 解析 NECext 文本中的 command 字节序列
2) 穷举“确认键 + 方向键映射 + 起点 + 边界策略”
3) 支持两种模型:
- basic: 仅 6x6 字母数字盘
- tv: 在 6x6 上方增加“清空/删除”特殊行(更贴近截图界面)
"""
from __future__ import annotations
import argparse
import itertools
import re
from dataclasses import dataclass
from pathlib import Path
CHAR_LAYOUT = [
list("ABCDEF"),
list("GHIJKL"),
list("MNOPQR"),
list("STUVWX"),
list("YZ1234"),
list("567890"),
]
BASIC_H = len(CHAR_LAYOUT)
BASIC_W = len(CHAR_LAYOUT[0])
TV_H = BASIC_H + 1
TV_W = BASIC_W
LEET_MAP = str.maketrans(
{
"0": "o",
"1": "i",
"3": "e",
"4": "a",
"5": "s",
"7": "t",
"9": "g",
}
)
@dataclass
class Candidate:
score: float
text: str
select_code: str
move_map: dict[str, str]
wrap: bool
start: tuple[int, int]
end: tuple[int, int]
model: str
backspace_code: str | None = None
def parse_codes(path: Path) -> list[str]:
codes: list[str] = []
pattern = re.compile(r"^command:\s+([0-9A-Fa-f]{2})\s+([0-9A-Fa-f]{2})")
for line in path.read_text(encoding="utf-8").splitlines():
m = pattern.match(line)
if m:
codes.append(m.group(1).upper())
return codes
def get_board_shape(model: str) -> tuple[int, int]:
if model == "basic":
return BASIC_H, BASIC_W
if model == "tv":
return TV_H, TV_W
raise ValueError(f"unknown model: {model}")
def apply_select(model: str, r: int, c: int, out: list[str]) -> None:
if model == "basic":
out.append(CHAR_LAYOUT[r][c])
return
if r == 0:
if c <= 2:
out.clear()
elif out:
out.pop()
return
out.append(CHAR_LAYOUT[r - 1][c])
def move_pos(r: int, c: int, direction: str, rows: int, cols: int, wrap: bool) -> tuple[int, int]:
if direction == "U":
nr, nc = r - 1, c
elif direction == "D":
nr, nc = r + 1, c
elif direction == "L":
nr, nc = r, c - 1
else:
nr, nc = r, c + 1
if wrap:
return nr % rows, nc % cols
return max(0, min(rows - 1, nr)), max(0, min(cols - 1, nc))
def decode_text(
codes: list[str],
select_code: str,
move_map: dict[str, str],
start: tuple[int, int],
wrap: bool,
model: str,
backspace_code: str | None = None,
) -> tuple[str, tuple[int, int]]:
rows, cols = get_board_shape(model)
r, c = start
out: list[str] = []
for code in codes:
if code == select_code:
apply_select(model, r, c, out)
continue
if backspace_code is not None and code == backspace_code:
if out:
out.pop()
continue
move = move_map.get(code)
if move is not None:
r, c = move_pos(r, c, move, rows, cols, wrap)
return "".join(out), (r, c)
def score_text(text: str) -> float:
if not text:
return -1.0
upper = text.upper()
letters = sum(ch.isalpha() for ch in text)
digits = sum(ch.isdigit() for ch in text)
repeated = sum(1 for i in range(len(text) - 1) if text[i] == text[i + 1])
markers = [
"FLAG",
"INFRARED",
"INFRA",
"SECRET",
"HIDE",
"CODE",
"KEY",
"FUN",
"IR",
]
marker_score = sum(upper.count(m) * 4 for m in markers)
readability = letters * 0.22 - digits * 0.18 - repeated * 0.5
return marker_score + readability
def to_flag_payload(raw_text: str) -> str:
text = raw_text.strip()
if text.upper().startswith("FLAG"):
text = text[4:]
return text.lower()
def to_leet_normalized_payload(raw_text: str) -> str:
return to_flag_payload(raw_text).translate(LEET_MAP)
def brute_force(codes: list[str], top_n: int, try_backspace: bool, model: str) -> list[Candidate]:
low_codes = sorted({c for c in codes if int(c, 16) <= 0x1F})
control_pool = [c for c in low_codes if c in {"0E", "15", "16", "17", "18", "19"}]
if len(control_pool) < 5:
control_pool = low_codes[:6]
other_codes = sorted(set(codes) - set(control_pool))
rows, cols = get_board_shape(model)
all_candidates: list[Candidate] = []
for select_code in control_pool:
rest = [c for c in control_pool if c != select_code]
for move_codes in itertools.combinations(rest, 4):
for direction_perm in itertools.permutations(["U", "D", "L", "R"]):
move_map = dict(zip(move_codes, direction_perm))
fallback_backspace = next((c for c in rest if c not in move_codes), None)
for wrap in (False, True):
for r in range(rows):
for c in range(cols):
text, end_pos = decode_text(
codes,
select_code,
move_map,
(r, c),
wrap,
model,
)
all_candidates.append(
Candidate(
score=score_text(text),
text=text,
select_code=select_code,
move_map=move_map,
wrap=wrap,
start=(r, c),
end=end_pos,
model=model,
)
)
if not try_backspace:
continue
backspace_candidates = list(other_codes)
if fallback_backspace is not None:
backspace_candidates = [fallback_backspace] + backspace_candidates
for backspace_code in backspace_candidates:
text2, end_pos2 = decode_text(
codes,
select_code,
move_map,
(r, c),
wrap,
model,
backspace_code=backspace_code,
)
all_candidates.append(
Candidate(
score=score_text(text2),
text=text2,
select_code=select_code,
move_map=move_map,
wrap=wrap,
start=(r, c),
end=end_pos2,
model=model,
backspace_code=backspace_code,
)
)
all_candidates.sort(key=lambda x: x.score, reverse=True)
return all_candidates[:top_n]
def print_trace(codes: list[str], cand: Candidate) -> None:
rows, cols = get_board_shape(cand.model)
r, c = cand.start
out: list[str] = []
select_idx = 0
print("[+] trace:")
for code in codes:
if code == cand.select_code:
select_idx += 1
before = "".join(out)
apply_select(cand.model, r, c, out)
after = "".join(out)
if cand.model == "tv" and r == 0:
action = "CLEAR" if c <= 2 else "DELETE"
elif len(after) > len(before):
action = f"CHAR({after[-1]})"
else:
action = "SELECT"
print(f" {select_idx:02d}: pos=({r},{c}) action={action} out={after}")
continue
if cand.backspace_code is not None and code == cand.backspace_code:
if out:
out.pop()
continue
move = cand.move_map.get(code)
if move is not None:
r, c = move_pos(r, c, move, rows, cols, cand.wrap)
print(f"[+] trace end pos=({r},{c}) text={''.join(out)}")
def main() -> None:
parser = argparse.ArgumentParser(description="IR challenge bruteforce decoder")
parser.add_argument(
"-i",
"--input",
type=Path,
default=Path(__file__).with_name("ir_challenge.txt"),
help="输入文件路径(默认:同目录 ir_challenge.txt)",
)
parser.add_argument("--top", type=int, default=20, help="输出前 N 条候选")
parser.add_argument(
"--model",
choices=["tv", "basic"],
default="tv",
help="解码模型:tv(含清空/删除) 或 basic(纯6x6字符盘)",
)
parser.add_argument(
"--try-backspace",
action="store_true",
help="是否额外穷举“某命令=退格”的情况(更慢)",
)
parser.add_argument(
"--trace-top1",
action="store_true",
help="打印第 1 名候选的逐次 select 轨迹",
)
args = parser.parse_args()
codes = parse_codes(args.input)
if not codes:
raise SystemExit("未解析到 command 码,请检查输入文件格式。")
print(f"[+] total codes: {len(codes)}")
print(f"[+] unique codes: {len(set(codes))} -> {' '.join(sorted(set(codes)))}")
print(f"[+] model: {args.model}")
print("[+] brute forcing...")
results = brute_force(
codes=codes,
top_n=args.top,
try_backspace=args.try_backspace,
model=args.model,
)
for i, cand in enumerate(results, 1):
backspace = cand.backspace_code if cand.backspace_code is not None else "-"
payload_raw = to_flag_payload(cand.text)
payload_norm = to_leet_normalized_payload(cand.text)
print(
f"{i:02d}. score={cand.score:.2f} "
f"sel={cand.select_code} move={cand.move_map} "
f"wrap={cand.wrap} start={cand.start} end={cand.end} "
f"bksp={backspace} text={cand.text}"
)
print(f" -> raw_flag: flag{{{payload_raw}}}")
print(f" -> leet_fix: flag{{{payload_norm}}}")
if args.trace_top1 and results:
print_trace(codes, results[0])
if __name__ == "__main__":
main()
|